A little over a year ago, I found myself developing automated tests for a back-end application that was using GraphQL. At the time, GraphQL was new to me—and for much of the tech industry—and there weren’t many established test automation patterns in place.
As an initial step, I decided to set some personal goals. Despite the necessary tests being technical in nature, I wanted to keep the test specification easy to read, dynamic, and flexible. I also wanted to create a set of test steps that were reusable and fit well in a query based GraphQL environment.
Below, follow along as I walk through what GraphQL is and how to solve some common challenges. If you’re new to GraphQL or don’t currently use it, I provide tips aimed at keeping your tests readable even in the most complex testing scenarios.
What is GraphQL?
GraphQL is an open-source data query language that was developed internally by Facebook in 2012 and publicly released in 2015. GraphQL is an alternative to REST, alleviating many of the pain points users experience while using it. GraphQL provides a complete and understandable description of the data in your API, gives clients the power to ask for exactly what they need and nothing more, makes it easier to evolve APIs over time, and enables powerful developer tools.
Who uses GraphQL?
Companies such as GitHub, Pinterest, Coursera, Spotify and even Pokemon Go use GraphQL APIs.
Why should you use GraphQL?
There are a few key reasons why you should consider using GraphQL. First, it has fewer roundtrips than REST—with GraphQL, you don’t have to send two separate requests to get data from two different endpoints. It also has a more elaborate typing system than REST. GraphQL has a balanced relationship between client and server and is natively discoverable.
Patterns and best practices
Below are some of the patterns I followed that helped keep my tests readable, dynamic and easy to maintain. Most of these patterns can be applied to any type of automated tests you are creating—not just for GraphQL based tests.
Be organized:
One thing that’s important when creating automated tests is to ensure they are well organized and readable. Grouping logical tests together and having consistent naming conventions is very important. When you have a handful of tests, it isn’t a big deal if they’re a little bit scattered. But think forward to a day when you have hundreds (or more!) tests. Therefore, it’s important to have an easy-to-follow naming convention and folder structure for your tests. Start these conventions early and stick to them, you’ll thank yourself later.
Readability:
Creating readable tests is important for many reasons. The ability to have your teammates read, understand and even contribute to your test specification is key. It fosters better team collaboration, allows for greater feedback and input and fits in well with Agile software development.
Recently I was creating a set of tests for a complex user story and was wondering if I had covered all the scenarios outlined in the acceptance criteria. Since I had written the tests using the Gherkin syntax I was able to send members of our team the GitHub link to the feature files and they were able to read and provide valuable feedback. In some instances, it fostered additional collaboration, found a defect or two, and allowed me to enhance some of the tests. Having readable tests like this also serves as additional documentation for what tests exist and can be used to trace tests back to acceptance criteria. Also, manual testers can easily review them to determine what types of test automation exist and help inform what tests should be part of the manual regression test suite.
Here are a few examples of some test scenarios. One scenario is more ideal than the other.
Write this:
Scenario: Query the system to determine system health
Given I run the "Healthy" query and store the results
Then The query result should include "true" in item "healthy"
And The query result should be truthy for item "healthy"
Versus this:
Scenario: Retrieve employee data from the API so that we can ensure it is correct
When I make the rest call: "GET" "https://my-api-end-point.com/api/employees"
Then response should contain: "{"employees":[ {"firstName":"John", "lastName":"Doe"}, {"firstName":"Anna", "lastName":"Smith"}]}"
The first scenario above is more readable and more consumable by a cross functional team. It’s also much more reusable since it takes a friendly query name as an input. The author of this scenario doesn’t need to be able to read or understand JSON or hashes in order to read or extend this scenario. The final two lines of the first scenario handle the parsing of the result of the GraphQL query but abstract away all the gritty details of it.
The second scenario forces the author to know about URLs and the expected inputs and responses of a given API. It is also more difficult to read and requires some technical knowledge along with some implementation detail knowledge.
Here are a couple more examples (this time without GraphQL):
Write this:
Scenario: Add a subpage via the site builder
Given I am logged in as user "standard_persona"
Given a microsite with a home page
When I select "Add subpage"
And I fill in "Title" with "Gallery"
And I select to submit the configuration form
When the component completes rendering
Then I should see a document called "Gallery”
Versus this:
Scenario: Add a subpage via the site builder
Given I am logged in
Given a microsite with a Home page
When I click the Add Subpage button
And I fill in "Gallery" for "Title" within "#document_form_container"
And I press "Ok" within ".ui-dialog-buttonpane"
Then I should see "Gallery" within "#documents"
Both above scenarios are readable. But pay close attention to the last several lines of each. The second scenario accepts inputs that require the author to have knowledge of the HTML or DOM. These are implementation details (the HOW vs. the WHAT) and should not be present in the gherkin statements. In the first scenario, all the author needs to specify is what they want the test to be or do. The details of HOW to do those things is the responsibility of the implementation code. This helps make the gherkin readable and consumable by the entire team.
Dynamic queries:
Since GraphQL is query based, you’ll end up with more than one query within your application. With GraphQL, every query has a schema—the shape characteristics of a given query (what data and types are available for the query).
When creating automated tests, I wanted to come up with a pattern that allowed me to store multiple query shapes, give them friendly names and also allow me to make them dynamic so that I could change the inputs to the query at runtime.
Note: I used Ruby to implement these tests and the terminology used below is Ruby. However, this pattern can be applied to other programming languages as well.
Given the above requirements, I decided to store each query I wanted access to in a Ruby module. I gave the module a friendly name (such as: HealthyQuery and ProductSalesDataQuery). Each query module contained the following:
- The query schema (the shape of the query).
- The query variables (the “arguments” for the query) a.k.a the dynamic portion of the query.
- Some helper methods that knew about the shape of the response coming back from the query. This was used to interpret/parse the query results.
I also created a wrapper around the Ruby GraphQL client. The client is necessary in order to execute GraphQL queries. It performs some basic functions for you such as schema validation and communication with the server.
Using all of the above, I was able to pass in friendly query names via the Gherkin statements, have those resolve to the correct module that contained the schema and then execute the query. I was then able to use some of the helper methods in that query module to help interpret the results. Since each GraphQL query has its own "shape,” it can also have a unique shape to the response as well. This will be in a form of a hash table. So, to me, maintaining the query result processing logic next to the query shape made a lot of sense.
To make the queries dynamic, (changing date ranges or data items going into the query) I added modifier Gherkin statements that had simple inputs for fields I wanted to change. Those inputs were then used to modify the query variables at run time. This allowed for queries that would return data for a given date range. That date range could change from scenario to scenario and all the test author would have to do is make a small change to the Gherkin statement.
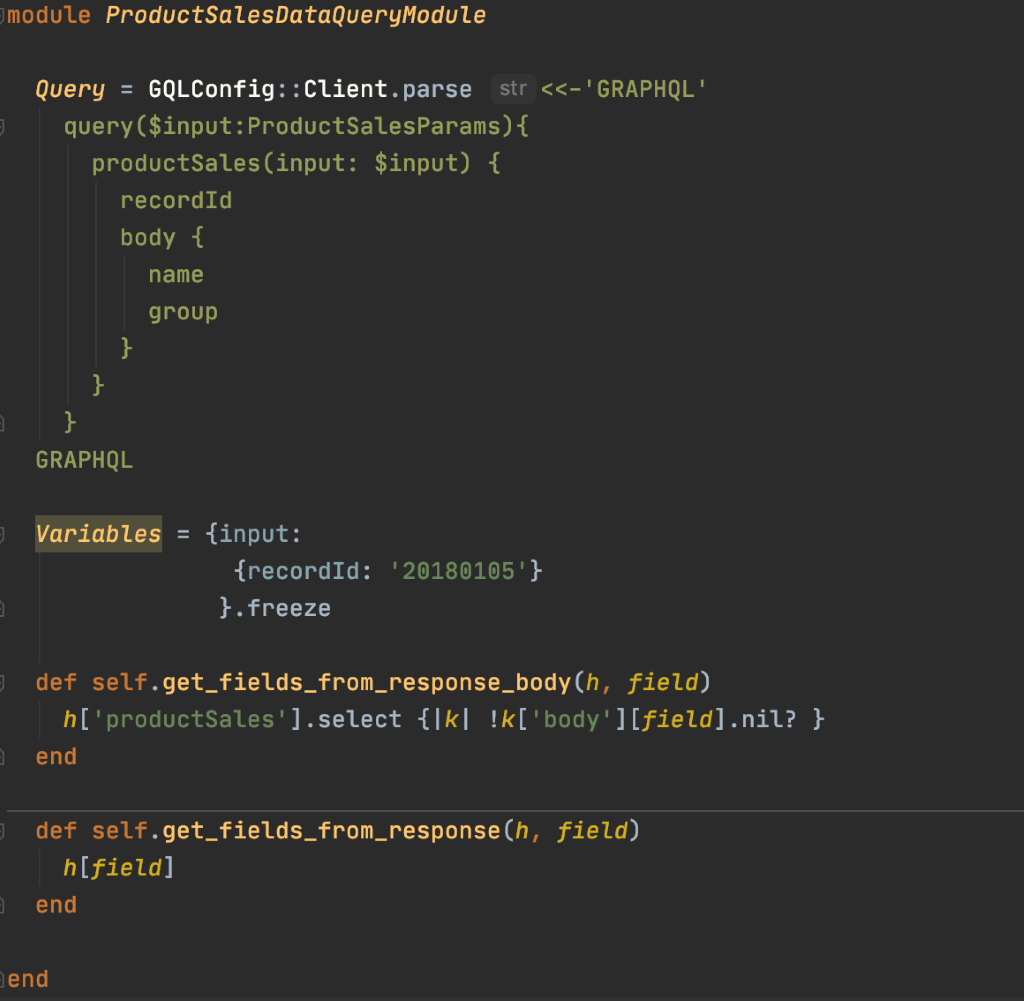
Here’s an example of what a basic query module, along with its helper methods might look like:
Summary:
By using these patterns, I was able to keep my test specifications (Gherkin) clean and readable. I was also able to build a flexible and reusable query model that helped keep my code more maintainable and manageable. Here are a few key takeaways:
- Write the Gherkin or test specification first. Write it without any preconceived notion of how you want to implement the test code. Write and design the Gherkin statements with readability in mind. Write the test specification you wish you had.
- With GraphQL, it’s important to be able to handle many query shapes and the associated responses in an orderly manner. This will help keep your implementation code D.R.Y. and concise. You may have 10 or more different queries you want to work with. Building a repeatable and maintainable query pattern is important. It should be easy to add/modify a new query should the need arise.
- Knowing how to work with hashes is important. Hashes will make up your queries and responses. You’ll also want to be able to update query variables at run time. These variables contain your ‘arguments’ (date ranges, IDs, etc). I found the ability to find deeply nested items in a hash and reading or replacing that value with a new value very important.
Have questions about the approach outlined above or want to have a chat about automated testing in general? Comment below or send a message. I’d love to chat.